摘要:将DeepSeek R1的强化学习和推理策略应用于自动驾驶,大幅提升规划性能和训练效率

项目主页:https://github.com/hustvl/AlphaDrive
论文链接:https://arxiv.org/abs/2503.07608
概述
OpenAI的o1和DeepSeek的R1模型在数学,科学等复杂领域达到甚至超过了人类专家的水平,强化学习训练和推理技术是其中的关键。而在自动驾驶,近年来端到端模型大幅提升了规划控车的效果,但是由于端到端模型缺乏常识和推理能力,在处理长尾问题上仍然效果不佳。此前的研究尝试将视觉语言模型(VLM)引入自动驾驶,然而这些方法通常基于预训练模型,然后在驾驶数据上简单的采用有监督微调(SFT),并没有在训练策略和针对决策规划这一最终目标进行更多探索。
针对上面的问题,我们提出了AlphaDrive, 一种针对决策规划的VLM的强化学习和推理训练框架。具体而言,AlphaDrive提出了四种针对规划的强化学习GRPO rewards。另外,我们提出一种基于SFT和RL的两阶段规划推理训练策略。在强化学习阶段,AlphaDrive展出的涌现的多模态规划能力,和DeepSeek R1的“Aha Moment”有相似之处,也证明了强化学习在自动驾驶大模型的应用潜力。据我们所知,AlphaDrive实现了首次将基于GRPO强化学习和规划推理引入自动驾驶规划,在规划性能和训练效率上都取得显著的进步。
AlphaDrive解决的研究问题
当前已有一些将VLM应用于自动驾驶的研究,大致可以分为两类,一类使用VLM实现对驾驶场景的感知理解,但是其主要关注感知任务;另一类则是直接使用VLM实现决策规划,但是不像端到端模型专门用于预测轨迹,大模型的输出空间是语言空间,并不擅长精确的数值预测,因此使用大模型直接预测轨迹可能会导致次优的结果,甚至有安全隐患;另一些工作则利用大模型做高维规划,即通过自然语言的形式规划自车未来的行为,例如“减速,向右变道”。这样可以避免上述的缺陷,但是并没有在训练方法上进行更多探索。它们大多采用SFT的训练方式,忽视了不同的训练策略与规划表现间的关系和训练开销问题。因此AlphaDrive主要尝试解决如下的问题:
(1)如何进一步提升大模型在自动驾驶决策规划的效果?
采用推理技术的OpenAI的o1模型在数学,编程等领域能力突出。另外,最近火爆的DeepSeek的R1模型采用的GRPO强化学习技术,不仅让大模型出现了“涌现智能”的时刻,实现了顶级的性能,同时训练开销远小于其他的同类模型。它们证明了推理技术和强化学习在大模型领域的巨大潜力。因此,我们想要尝试回答如下问题:如何将在通用大模型领域大放异彩的强化学习和推理技术应用于自动驾驶,尤其是决策规划,从而提升大模型在自动驾驶任务上的表现,并降低训练开销。
(2)如何设计针对驾驶规划的大模型强化学习策略?
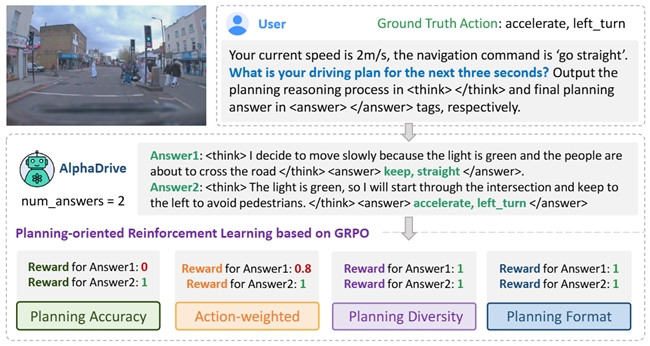
通过大量实验,我们发现直接将现有的强化学习技术在自动驾驶规划上效果不佳。我们认为主要有如下原因,首先,针对通用任务的强化学习reward设计并不适合于驾驶场景,例如对于视觉目标计数任务,reward可以简单的设计为判断模型回答的正确与否。但是对于驾驶而言,虽然规划也可以看作为多分类任务,但是由于不同驾驶行为的重要性存在区别,因此不能对于所有驾驶行为都赋予相同权重。另外,不像数学或者counting,规划可能并不存在唯一的正确解,例如在一段空旷的直道上,你可以选择匀速前进,也可以选择加速前进。因此硬性的判断模型规划结果和实际的操作是否一致并不是最好的选择。
(3)如何将大模型Reasoning技术引入决策规划?
在通用领域,像是数学或者编程,都拥有较多现成的reasoning数据可以利用,例如教科书的参考答案或者编程网站。但是在驾驶领域,目前几乎没有现成的决策推理过程的数据,采集这种数据的成本非常高昂,需要大量人工标注,因此推理技术的使用也很难直接复用现有方案。
AlphaDrive的关键创新
• 我们提出了AlphaDrive,一个用于自动驾驶高维规划的视觉语言大模型,据我们所知,AlphaDrive首次将基于GRPO的强化学习和规划推理引入基于大模型的自动驾驶任务,大幅提升了模型的规划表现和训练效率。
• AlphaDrive提出了四种强化学习GRPO rewards,分别是规划准确率reward,action权重reward,输出多样性reward和规划格式reward。这些优化的reward设计让GRPO更适合于自动驾驶规划任务。
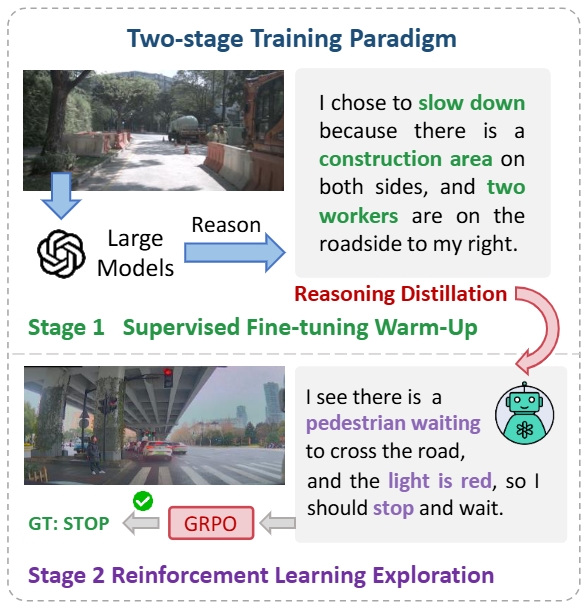
• 我们提出了基于知识蒸馏的SFT和RL的两阶段推理训练策略,通过使用云端大模型生成的少量高质量规划推理数据,相比于仅使用RL进行训练或者没有推理过程,AlphaDrive达到了更好的规划效果。
AlphaDrive的实验及应用效果
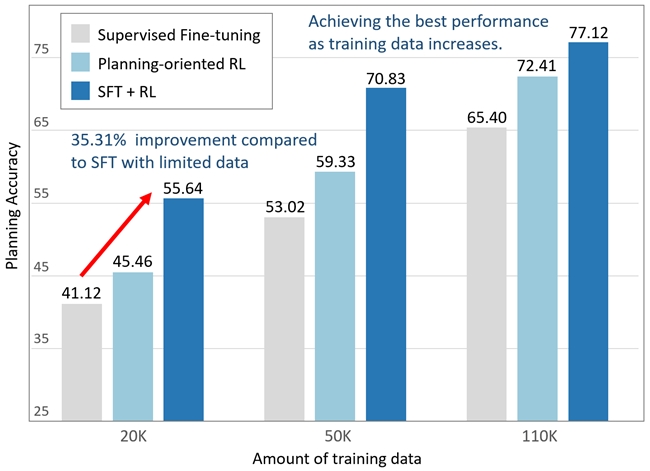
基于真实驾驶场景的大规模数据集上的实验和消融验证了AlphaDrive的先进性。与SFT训练的模型相比,AlphaDrive的规划准确率显著提升了26%,并且在仅使用1/5的训练数据的情况下,性能比SFT训练的模型高出35%。另外,在强化学习阶段,AlphaDrive展出的涌现的多模态规划能力,和DeepSeek R1的“Aha Moment”有相似之处,证明了强化学习在自动驾驶大模型的应用潜力。

未来探索方向
AlphaDrive初步探索了大模型强化学习和推理技术在自动驾驶领域的应用。下一步,我们将尝试将AlphaDrive从VLM拓展到VLA,实现一个统一的理解、决策、规划的自动驾驶大模型。
参考文献
[1] Guo D, Yang D, Zhang H, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning[J]. arXiv preprint arXiv:2501.12948, 2025.
[2] OpenAI, Learning to reason with LLMs, https://openai.com/index/learning-to-reason-with-llms.
[3] Shao Z, Wang P, Zhu Q, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models[J]. arXiv preprint arXiv:2402.03300, 2024.




